
Digitalising the Arabic family tree
Adam Research Centre was founded by Dr. Hasan Alamri, an anthropologist whose passion is discovering the past of Arabic tribes and the evolution of the geographic region. This led him to collect and index hundreds of historical artefacts (books, scrolls, tombstones, … ). Building the Arabic family tree became the core of the institute.
As the operation grew, he and his team started exploring how they could increase the productivity of the researchers, improve the quality of collected data, and expand their options for reusing the data.
In the beginning, researchers kept all the data in spreadsheets. However, this approach was not scalable, easily corruptible, and lacked proper referencing to meet scientific standards. With a project of this scale, the sole quantity of the data, let alone its complexity, quickly made that kind of solution insufficient. They turned to us to help them digitalize their project.
Understanding the Existing Process
interviewing the adam team
We talked to business people, scientists and project managers to understand the business, the team’s needs, and pain points.
observing & Mapping their workFLOW
To digitalize the process of collecting and referencing artifacts, we closely observed their workflow, watching each step in detail. This hands-on approach helped us identify opportunities for improvement and ensure the digital tool would be both efficient and effective.
Deliverables
defined INTERNAL team PROCESSES
We worked together on co-creating a system and internal processes that will support data integity, referencing while increasing scalability of the operation.
Roadmap with timeline and budget estimations
based on the defined scope and priorities.
Low-fidelity PROTOTYPES
for all possible use cases.
System architecture plan
to define the technical foundations of the product.
Implementation
The Database Structure and Millions of Nodes
The specifics of this product made for some distinct challenges during the development.
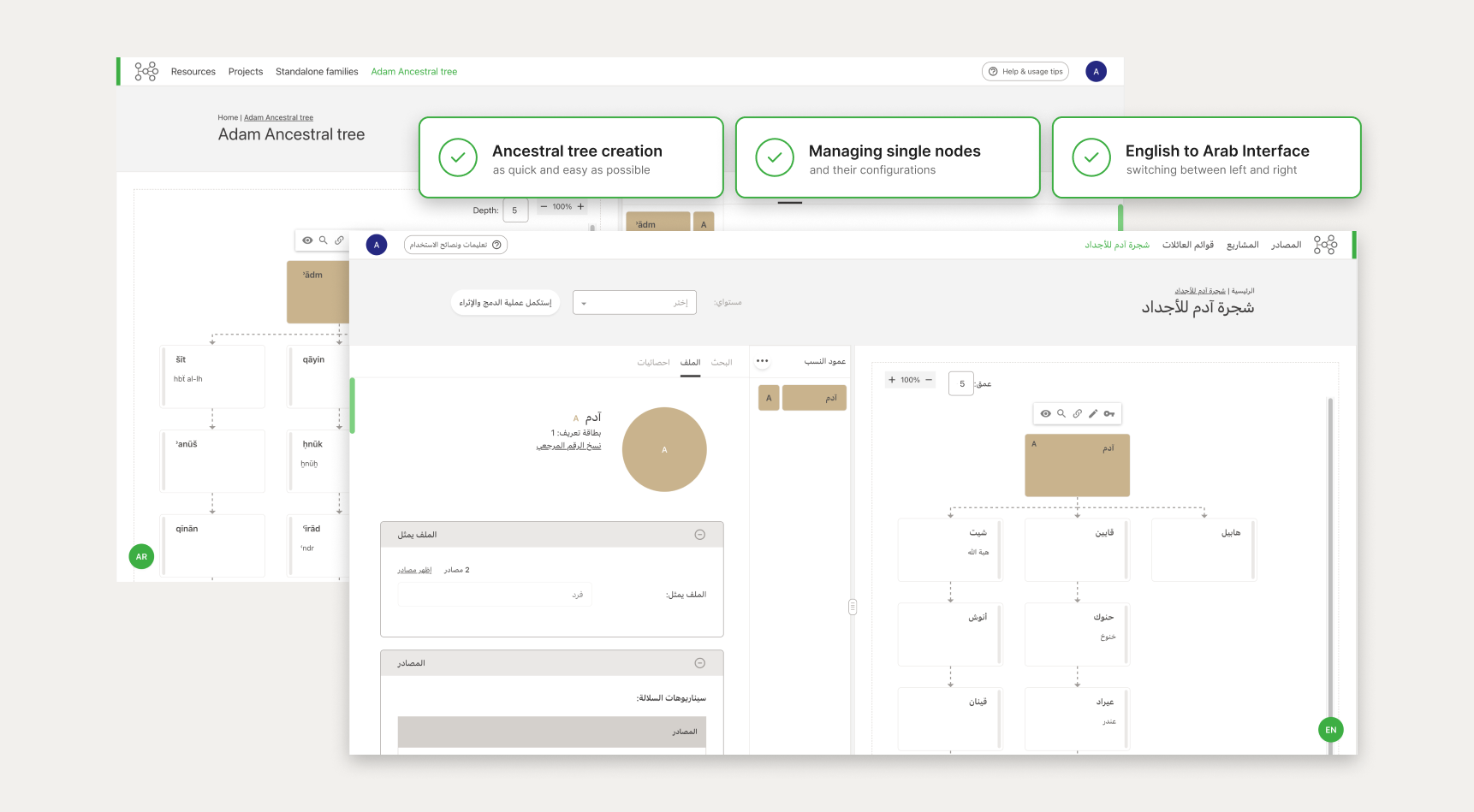
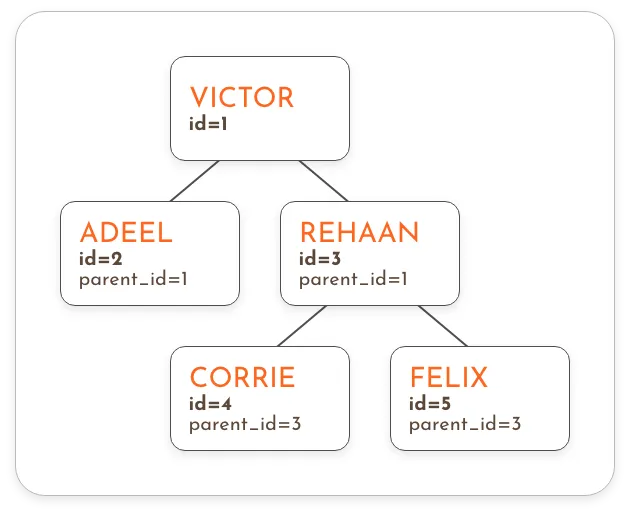
The Tree Database Structure
The system has two parts: the “master tree” and “working branches”. When a working branch is ready and all its data is confirmed, it has to be merged into the master tree. Making sure the database didn’t get corrupted was top priority.
Millions of Nodes
In this complex system, performance and scalability were also at the forefront of our efforts. We compared three different approaches to storing the data and decided to go with the form of arrays.
Open Code System
As the researchers' workflow wasn’t set yet, the structure of the code had to allow later changes and optimisations. We had to constantly make sure we didn’t lock ourselves into an assumed but not yet established process.
Ongoing Work
The researchers' work did not stop during our development. They worked simultaneously in both systems, which also meant constant imports and exports, so we had to be extremely careful to always display accurate data.


Newsletter
Join Beka, our resident goat on her quest to understand the mysteries of building & launching digital products. From Business & Design to Engineering, Processes & Teams.
